Introduction
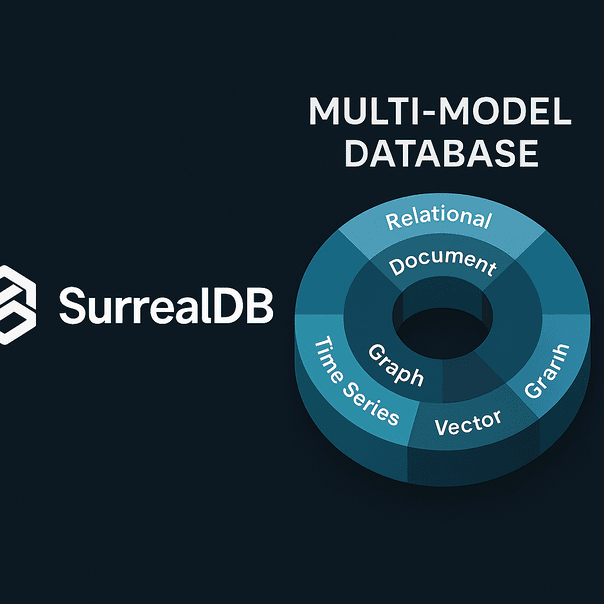
SurrealDB is an open-source, multi-model database that combines document, graph, relational, vector, geospatial, and time-series capabilities. It’s particularly well-suited for AI developers building local-first applications, agentic workflows, or LLM-powered backends. This guide walks through what makes SurrealDB unique, how to install and run it locally, and how to use it with LLMs (like those served via Ollama).
In the ever-evolving landscape of AI and intelligent agent development, SurrealDB is positioning itself as a powerful backend solution tailored to modern application needs. As AI workloads increasingly demand flexibility, speed, and multi-modal data handling, SurrealDB’s architecture offers a compelling alternative to traditional relational or vector databases.
We recently explored SurrealDB in a local development setting—particularly for AI and agentic applications using open-source LLMs—and walked away impressed with its performance, simplicity, and versatility.
Why SurrealDB for AI Applications?
SurrealDB simplifies full-stack AI development by unifying multiple data paradigms under one database:
- Relational for structured metadata (e.g., users, sessions)
- Document/Graph for relationships and nested content
- Vector for similarity search in retrieval-augmented generation (RAG)
- Embedded + distributed deployment options
Ideal for:
- Chatbot memory and context persistence
- RAG pipelines with open-source embedding models
- Agent state management
- Privacy-first, local deployments
What is SurrealDB?
SurrealDB is a native, open-source multi-model database that combines the capabilities of several traditional data models—relational, document, graph, time-series, vector, and geospatial—under a single query interface known as SurrealQL. SurrealQL is a flexible, SQL-like language that’s intuitive yet expressive, capable of handling structured queries across multiple data types and relationships.
While that might sound complex, the real magic is how lightweight and developer-friendly it is. SurrealDB runs smoothly on local machines, supports embedded use cases, and also scales to distributed environments.
Architectural Overview
One of SurrealDB’s defining features is its layered architecture that separates compute and storage. Here’s a breakdown:
- The compute/query layer handles parsing, execution, and transaction management.
- The storage layer supports a range of engines such as:
- RocksDB (for embedded, in-memory scenarios),
- TiKV (for distributed use cases),
- IndexedDB (for browser-based applications).
This separation enables it to scale from simple single-node applications to full-scale distributed systems—all with the same interface and logic.
You can use SurrealDB:
- As a backend database for your app,
- As a full backend-as-a-service (BaaS) with authentication and permission layers,
- Or embed it directly into local desktop or browser-based AI agents.
Step 1: Install SurrealDB Locally
On Ubuntu (or other Linux flavors):
curl -sSf https://install.surrealdb.com | shMake the binary accessible globally:
sudo mv surreal /usr/local/bin/Verify installation:
surreal versionYou should see output like:
surreal 1.0.0-beta.9 (linux-x86_64)Step 2: Start SurrealDB Locally (In-Memory)
For development/testing:
surreal start --log debug --user root --pass root memoryTo use persistent file storage:
surreal start --log debug --user root --pass root file:/path/to/dataAccess it via HTTP on port 8000 by default.
Step 3: Use SurrealDB with Python
Install the Python client:
pip install surrealdbSample Python Code
from surrealdb import Surreal
import asyncio
async def run():
db = Surreal()
await db.connect("http://localhost:8000/rpc")
# Sign in
await db.signin({"user": "root", "pass": "root"})
await db.use("test", "test")
# Create a document
await db.query("CREATE message CONTENT { text: 'Hello from SurrealDB!' }")
# Query it back
results = await db.query("SELECT * FROM message")
print(results)
asyncio.run(run())Step 4: Using SurrealDB for Vector Storage
Use LLM embeddings (e.g. from Ollama or HuggingFace):
Example with OpenAI Embeddings:
from openai import OpenAI
import numpy as np
# Assume you have your API key and text
response = openai.Embedding.create(
input="This is a sample text",
model="text-embedding-ada-002"
)
embedding = response['data'][0]['embedding']
await db.query("CREATE vector_doc CONTENT { id: 'doc1', text: 'This is a sample text', embedding: $embedding }", {"embedding": embedding})You can then do cosine similarity filtering with SurrealQL (when supported).
Use Case: Local AI Chatbot with Ollama + SurrealDB
- Serve a local model using Ollama:
ollama run llama3- Generate summary/response
- Convert text to embeddings
- Store in SurrealDB
- Query via vector similarity to augment prompts
Benefits Recap
- ⚡ Lightweight & Fast: Great for edge and local workflows
- 📦 Multi-model: One database to rule them all
- 🧠 LLM-Ready: Ideal for memory and RAG use cases
- 🔒 Private by Default: Local execution with zero cloud dependency
Developer Experience
Here’s what stood out to me:
- ✅ Blazing fast setup — Install, run, and connect in under 5 minutes.
- ✅ Powerful schema system — Define document types, indexes, constraints, and relationships natively.
- ✅ First-class support for vectors — You don’t need Pinecone, Qdrant, or external vector DBs.
- ✅ Great for prototyping — The in-memory mode is perfect for testing ideas without provisioning cloud infrastructure.
- ✅ Multi-language SDKs — I used Python, but there’s support for Node.js, Rust, Go, and more.
I also appreciated the fact that you can run SurrealDB locally and fully offline—a major plus for privacy-focused, edge-based, or regulated applications.
Sample Use Case: Local AI Chatbot with Embedded Memory
To showcase its utility, I built a basic chatbot using Ollama + SurrealDB. Here’s how it worked:
- A user input is processed by Ollama.
- The LLM generates a response and summary.
- That summary is converted into a vector and saved to SurrealDB.
- When the chatbot is restarted, it recalls past interactions by querying SurrealDB using vector similarity.
Even in this early stage, the speed was impressive, and memory recall from the database felt snappy and accurate.
This makes SurrealDB a viable choice for memory-augmented agents, AI assistants, and tools that need persistent knowledge without relying on external APIs.
Final Thoughts
SurrealDB is a Swiss army knife for AI engineers who want full control of their data, performance, and stack. Whether you’re prototyping an AI assistant, building a custom memory engine for agents, or integrating multimodal inputs, this database offers a clean and unified solution.
Checkout their Github link. Also, checkout Kiro which is an intelligent agent orchestration platform designed to simplify building, managing, and deploying autonomous AI workflows across diverse environments.